可解释机器学习-Task02 ZFNet 深度学习图像分类算法
0x00 Abstract
- 纽约大学 ZFNet,2013 年 ImageNet 图像分类竞赛冠军模型。对 AlexNet 进行改进的基础上,提出了一系列可视化卷积神经网络中间层特征的方法,并巧妙设置了一系列实验,从各个角度基于可视化,对卷积神经网络各中间层提取的特征进行了相关分析。
- 论文:Visualizing and Understanding Convolutional Networks(可视化并理解卷积神经网络)
- 主要贡献:提出了一种巧妙的可视化卷积神经网络中间层特征的可视化方法与技巧
0x01 ZFNET 网络结构
网络结构:在 AlexNet 的基础上,对卷积核、步长等做了一些调整

后文会提到为什么要对 AlexNet 做以上修改,以及修改的根据是什么。
0x02 可视化卷积中间层的方法
 如图,对于想要可视化的中间层(由卷积、激活、池化获得的),执行反池化、反激活、反卷积操作,重构回原始输入的特征空间,获得人类可以理解的特征(图片)。
如图,对于想要可视化的中间层(由卷积、激活、池化获得的),执行反池化、反激活、反卷积操作,重构回原始输入的特征空间,获得人类可以理解的特征(图片)。
1. 反池化
池化操作是用的 MaxPooling,将最大值保留。
那么如何反池化呢?
在正向池化的时候将对最大值的原始像素位置记录,反池化时,根据各个最大值的原始位置重新放回去。

2. 反激活
仍然使用 ReLU 激活函数。
3. 反卷积
使用原来正向卷积的卷积核的转置(行列互换)。 转置卷积没有需要学习的参数,是一个完全无监督的过程。
什么叫卷积核激活最大?
0x03 中间卷积层可视化的实验
Feature Map: Feature Map(特征图)是输入图像经过神经网络卷积产生的结果,表征的是神经空间内一种特征;其分辨率大小取决于先前卷积核的步长。
层与层之间会有若干个卷积核(Kernel),上一层中的每个 Feature Map 跟每个卷积核做卷积,对应产生下一层的一个 Feature Map。
Feature Map 的含义在计算机视觉领域基本一致,可以简单译成特征图,例如 RGB 图像,所有像素点的 R 可以认为一个 Feature Map(这个概念与在 CNN 里面概念是一致的)。
彩色图:从原始数据集找出的,能使特定层的某些卷积核激活最大的九张图片(九张为一组)。
灰色图:将九张图片 feed 到网络中,随后从特定层找到其 Feature Map,然后使用反卷积的技巧重构回原始输入像素空间得到的可视化图片。
1. 第一层

图中上面的 3*3 的图是第一层卷积核,(1, 1) 对应着下图左上角的 9 个 Patch,其他的以此类推。可见 (1, 1) 卷积核主要提取左上角到右下角的边缘特征,(3,2) 卷积核主要提取绿色的特征,可见第一层卷积层主要提取边缘、颜色这种底层特征。
2. 第二层(开始使用反卷积做可视化)

可以看到卷积核开始提取晚霞色、圆环、垂直的线等等的形状特征。
左侧灰色图与右侧的彩色图一一对应,灰色图有颜色的位置即代表像素被还原回去的位置,可以发现是可以与彩色图里的特征形成对应,也可视化了该层的 Feature Map 到底是提取到了怎样的特征。与第一层的特征相比好像高级了一些。
3. 第三层
可以发现,到了更深的层时,提取到的特征更加复杂、高级,或者说更富有语义信息。

该层提取到了车轮、人体形状、文字等等的一些特征。
4. 第四层和第五层

第四层提取到了比如狗脸、鸟腿、其他动物的腿的一些特征。
第五层甚至提取到了草地的背景特征(而非前景特征),以及眼睛的特征。
而且相比于其他卷积核,他们的彩色图片基本有一定的相似性,但如下提取草地背景的卷积核的彩色图片可以说是有较大差异的。


可见随着卷积层的变深,所提取到的特征更加高级,更加富有语义性。
0x04 相关的分析
1. 训练过程中中间层卷积核的变化

灰色图依然从数据集中挑选出来激活最大的 Feature Map,然后使用反卷积重建出在原始像素图片中可视化的结果。图中每一层(Layer 1,Layer 2...)的一列是挑选出的数个卷积核,一行是该卷积核随着训练迭代的变化。可以看到低层的卷积核很快收敛,高层的卷积核在刚开始的训练过程中提取不到特征,要训练多轮才可以收敛并提取到特征。
2. 不变性分析
对原图做平移、缩放、旋转,对某一层的 Feature Vector(由 Feature Map 拉直获得)的变化,使用变化前与变化后的 Vector 的欧氏距离来度量。

做平移时,第一层的卷积核比较敏感,Feature Vector 变化较为剧烈,而第七层的卷积核呈现出较为缓慢的类似于线性的变化,说明该层已经不是那么注重于表面的特征变化,而是更加关注高级的语义信息。
做旋转时,图像每旋转 90 度,准确率会出现一个峰值,说明了对称性,当某些特征(比如电视机)是对称,或者翻转过去,依然呈现为正的一个长方形时,网络是可以捕获到这种信息的。
3. 对 AlexNet 的优化
通过对 AlexNet 的第一层与第二层的卷积核做可视化,发现存在一些卷积核失效,或者是由于步长过大,出现混淆网格样式的卷积核,基于此,本文对卷积核大小以及步长做了一定调整,并改善了以上发现的问题。

对步长以及卷积核大小做了修改之后,第一层卷积层中失效的卷积核变少了。 
对步长以及卷积核大小做了修改之后,第二层中混乱网格的卷积核去除了。 
4. 局部遮挡敏感性分析
用一个小灰方块在图像上进行遮挡,并分析该遮挡对 Feature Map 与预测结果造成的影响,探究了网络对遮挡的敏感性。

第三列黑框中的是未经遮挡时的第五层 Feature Map 重构的可视化,黑框之外的三个是同样可以使得激活最大的其他三个无关的图片。
第二列是灰色挡板在不同位置时,对各自获得的 Feature Map 叠加起来获得的热力图。当遮挡住重要信息(当前层主要提取的特征,如狗脸、文字、人脸)时,Feature Map 中相应的值自然会降低,在热力图中呈现为蓝色。从而验证了神经网络对遮挡的敏感性。
5. 局部遮挡相关性分析
如果对不同的图片(狗)遮挡住同一位置(左眼、右眼、鼻子等),对网络的影响是一样的,那么说明网络对于各种狗脸图像中的左眼、右眼、鼻子的部位定义了一种隐式相关性。
如何验证呢?

我们将遮挡前与遮挡后不同层的 Feature Vector 做一个差值 这里会难理解一些,配合论文里的公式、计算方法与解释会更好理解。
还有一点要注意的是,随机遮挡时,第五层的影响是较大的,但到第七层时,影响变小了一些,说明更加深层的网络更加关注高级的语义信息,而不仅仅是表面的一些变化。
0x05 模型实验结果
1. 实验对比

与 AlexNet 相比,改进后的模型获得了较大的提升。
2. 消融实验

上面一栏是对 AlexNet 做的一些实验:
前五行:去掉少量卷积层或者全连接层对于错误率的影响是不大的,但如果同时去掉(3,4,6,7)层的卷积与全连接,会有较大的影响。说明网络的深度对于预测准确性的影响还是较为关键的。
七行:如果将 Layer 6, 7 的神经元个数设置的非常大会造成过拟合,可以看到 Train Top-1 的错误率为 26.8,但 Val Top-1 的错误率却达到了 40.0。
下面一栏有关本文的一些实验,可以看到在验证集达到了一个最低的错误率。
3. 迁移学习实验
探究在 ImageNet 上训练的 ZFNet 能否泛化到其他数据集,即进行迁移学习与微调。

在 ImageNet 上训练的 ZFNet 拿到 Caltech-101 数据集上,保留前面的层,只对 Softmax 分类层做重新训练,可以看到取得了比原作要好的效果。但如果只保留 ZFNet 模型结构,清除模型参数,在 Caltech-101 上重新训练网络,可以看到效果并不好。
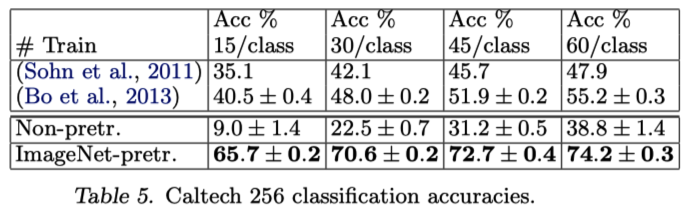
在 Caltech 256 上也取得了远高于原作的效果。

有意思的是,每个类别只需要 6 张图片训练,就可以达到原作(每个类别 60 张)最好的效果。也就是说使用迁移学习,可以用很少的数据,就达到较好的性能,如果拥有更多的数据,就可以达到更好的性能。

但如果以同样的方式照搬到 PASCAL 数据集,其实效果没那么好,因为这个数据集中每张图片有多个物体,而 ImageNet 与前两个数据集都只有一个物体(是相似的)。因此在不同情况的数据集上,对损失函数等做一些调整,才会达到不错的效果。
4. 网络中不同层对于分类的有效性
全连接层起到线性分类器的作用,SVM 或者 Softmax 同样可以起到分类的作用。在实验中可以看到,越深的层对分类结果起到越发有效的作用。

Conclusion
ZFNet 提供了可视化卷积模型中间层的技巧,使用反卷积、反池化、反激活将中间层的 Feature Map 重构到原始输入图像的像素空间,变成人类可以理解的图像。并且提供了很多有趣的实验方法,比如分析局部遮挡的敏感性与相关性,基于可视化结果优化模型结构,做迁移学习的实验方法等等。是很有启发性的一篇优秀论文。也感谢子豪兄的讲解。